When Azure Data Factory (ADF) released the managed virtual network feature for Azure integration runtimes, it seemed like a no-brainer at first. Who wouldn’t want to isolate their ETL traffic without the need to manage the network infrastructure? A recent migration project made me look much closer look at this feature, and the cost implications of using it…
The back-story
One of my customers is a not-for-profit company, and while the cloud provides the necessary infrastructure back-bone to keep the team lean, we are always trying to tweak and optimize costs anywhere we can. All the little things add up quickly, and if you don’t pay attention to the details you could end up paying a lot more than you anticipated.
Some time ago, I recommended that they move from Azure Analysis Services to Power BI Premium Per User and from Integration Services (hosted in an Azure VM) to Azure Data Factory. With these types of recommendations I typically like to show the return on investment (or that my work pays for itself over time) and I provided the following cost analysis:

We were running SSIS in an Azure VM, spinning the VM up and down as required to run the ETL processes. A third-party SSIS component was used to extract data out of Dynamics 365 CRM, and accounted for a significant part of the yearly costs. I blogged about the reasons why I think it’s worth moving from Azure AS to Power BI PPU before, and combined with the move to Azure Data Factory I estimated a cost reduction of almost 35%.
After deploying the solution I noticed that our daily ETL costs were significantly higher than I thought it would be, and that started a little rabbit-hole exercise to figure out why. The image below shows the daily ADF charges, and I’ve highlighted Mar 4th because it was the first date of regular operations after our deployment. The spikes you see before & after that date is either due to testing or rerunning a failed process.

The process
A few initial attempts at finding quick wins were not successful, and included the following:
- Moved the Integration Runtime – Our first and most time consuming (i.e. expensive) step was to extract data into a Staging database. The Azure Integration Runtime was in a different region than the Staging database (long story), and I was hoping that by moving it closer to the destination we could make a significant impact. In our case is did not, although I’d still recommend that you host the Integration Runtime as close to the data (source or destination) as you can.
- Shortened our extract window – We use a sliding-window approach (see this blog post for more details) and extract the last x number of days (based on a parameter) from all data sources. I tweaked this to reduce the amount of records we transfer, but this alone didn’t make a noticeable difference.
At this point it seemed like it would be a long road to get to the bottom of it, and the native logs in ADF were not very useful as they only allow you to look at one activity’s details at a time. A very helpful blog post by Meagan Longoria prompted me to look into Log Analytics as a means to a better look at the execution data underneath the covers, and I set up a separate Data Factory to isolate and run a specific portion of the ETL process…enabling Log Analytics as Meagan’s blog post describes.
I used the following KQL query to isolate the Copy activities with Succeeded status, and the results are posted below:
ADFActivityRun
| extend Output = parse_json(Output)
| where Start >= datetime(2022-03-10) and Start < datetime(2022-03-12)
| where ActivityType == "Copy"
| where Status == "Succeeded"
| order by Start asc
I’ve highlighted the interesting parts in the image, and here are the details around it:
- duration – This metric within the billingReference section tells me how many DIU Hours this pipeline is consuming, and important because this is what I’m going to pay for.
- copyDuration – This is how long the Copy activity took to complete, rounded to the nearest second.
- integrationRuntimeQueue – The value of zero is good here, and means that we didn’t have to wait for the Integration Runtime. If you see a high number here on many of your Copy activities, it means that you’re waiting for resources from the IR and probably need to scale your resources up.
- usedDataIntegrationUnits – Even though we’ve set the Copy activity in our pipeline to use 2 DIUs, it seems like it used 4. This is important and also the first hidden cost of a managed VNET. Irrespective of your DIU setting in the activity it will always use 4 DIUs at minimum, which can make a pretty big difference if you take into account that execution times are also rounded up to the nearest minute.
Although good information, we need to dig a little deeper to see why it’s taking 88 seconds to transfer only 63,000 rows. Expanding the executionDetails section reveals more interesting facts:

Whoa, there’s another queue metric here and it’s different!! This Copy activity was sitting in a queue for 53 seconds before it even started, and the reason why is buried deep inside the documentation: “By design, Managed VNet IR takes longer queue time than Azure IR as we are not reserving one compute node per service instance, so there is a warm up for each copy activity to start, and it occurs primarily on VNet join rather than Azure IR.”
What this means is that instead of just a single warm-up for the IR itself, each Copy activity has to wait because the compute node is not reserved and has to be created again. You’re essentially spinning up the network infrastructure for each individual Copy activity, independently. Looking at the queue durations across activities highlight this nuance even more:
ADFActivityRun
| extend ExecutionQueueTime = extractjson('$.executionDetails.[0].detailedDurations.queuingDuration', Output, typeof(decimal))
| extend TotalDuration = extractjson('$.executionDetails.[0].duration', Output, typeof(decimal))
| extend PercentageQueueTime = round(ExecutionQueueTime / TotalDuration * 100)
| where Start >= datetime(2022-03-10) and Start < datetime(2022-03-12)
| where ActivityType == "Copy"
| where Status == "Succeeded"
| order by Start asc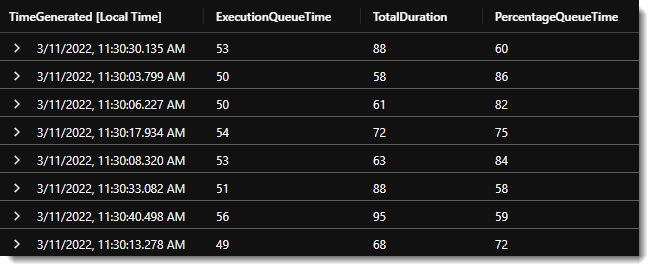
Across the 8 Copy activities in my very first test run, a whopping 72% of the total time was spent waiting. Things improved slightly over the course of the next week as I experimented with different settings, but queue times varied wildly and on average the Copy activities spent 40% of the total execution time waiting in a queue.
Compared to an IR without the managed VNET, queue times were at an average of 15% for a DIU setting of 4 and 24% for a DIU setting at 2. Understandably the queue times will be longer at 2 DIUs, as you may be waiting for resources to become available.
Because of the consistently longer queue times, the Integration Runtime with the managed VNET was at best 2 times more expensive as the non-managed counterpart…at worst about 10 times more expensive. Execution times were faster at 2 DIUs and without the managed VNET than it was with the managed VNET at 4 DIUs.
Should we stop using managed VNETs in ADF?
I’m not trying to advocate for you to stop using the managed VNET option, but you should be aware of the potential costs involved and what you are really getting with this feature. Here are a few things to think about:
- Public Data Sources: In our case, data was extracted from Dynamics 365 CRM and the data still had to travel via public networks. If you have a publicly hosted source system, how much is the additional isolation worth if it only protects the data once it’s within the Azure network. I’m no networking expert, but in my opinion it’s probably not worth it for public sources.
- Private Endpoints: If you are transferring data between supported cloud resources and not using private endpoints, then you’re probably not as protected as you think you are with only the VNET option enabled. The two features go hand-in-hand and should be used in combination.
- Cost vs. Benefit: If you look at the Azure Pricing Tool (West Central US), you’ll see that the cost/hour is 200 times higher for pipeline activities and even more for external pipeline activities when it comes to managed VNET Integration Runtimes. Weigh that up against the benefits you are getting from having the VNET in the first place, and the type of data you are transferring. Each situation is unique and should be treated as such.
The outcome
Our ultimate decision was to go with the non-managed VNET Integration Runtime, and the image below shows the significant impact it had on our daily runtime costs, going down from around $12 to just about $3…4 times less!

Very interesting – glad I moved to drag and drop for the win !
Haha, very funny Dan…you’ve always been on the lazy end 🙂
I think i prefer to think of it as a drive towards simplicity !
Great article, one question though if you are connecting with PPU account to D365 why not use Dataflow instead of ADF?
Thank you! We have multiple data sources, and a data warehouse with complex logic (like tracking history). Dataflows would not have been the appropriate solution.
Hi, how would someone actually switch to VNET is there are an good article on that?
You’ll have to recreate the IR. No articles that I know of, unfortunately.
With SQL MI, there is no other option to connect the ADF. and the cost spirals faster
Could you elaborate? I have a customer with SQL MI and are using a public Azure IR without any issues…
Thanks for good article.